本节我们主要介绍C++中类的继承与派生,内容相对简单,但是这些都是第五章多态的基础。
何为“继承”与“派生”
派生类是对基类进行扩充和修改得到的。 所谓扩充是指在继承基类成员的基础上,可以继续添加新的成员变量和成员函数;所谓修改是指在派生类中,可以重写基类继承来的成员。注意派生类的成员函数并不能访问基类的私有成员,但是实际上私有成员仍然被继承,只是不能进行访问。
1 2 3 class 派生类名:继承方式说明符 基类名{ ... };
继承方式说明符有三种,分别为public、private、protected。我们一般会使用public公有继承,下面我们介绍一下不同派生方式会导致基类的成员在派生类中的可访问范围属性不同,如表1所示:
基类成员
继承方式
public
private
protected
私有成员
不可访问
不可访问
不可访问
保护成员
保护
私有
保护
公有成员
公有
私有
保护
表1:不同派生方式下基类成员在派生类中的可访问范围属性
例如,基类的共有成员在进行私有继承后,在派生类中就变为了私有成员。一般情况下,都会选择Public进行成员的继承,这样更加易懂一些,而且并不会对安全性有太大的影响。
1 2 3 4 5 6 class CBase { int v1,v2; }; class CDrived :public CBase{ int v3; };
CDrived在存储空间中的示意图如图1所示:
图1:派生类对象的内存空间示意图
在这一小节的最后,我们通过一个学生管理系统的程序来进一步理解派生和继承的基本方式。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 #include <iostream> #include <string> using namespace std;class CStudent {private : string name; string id; char gender; int age; public : void PrintInfo () void SetInfo (const string& name_,const string& id_,int age_,char gender_) string GetName () { return name; } }; class CUndergraduateStudent :public CStudent{private : string department; public : void QulifiedBaoYan () cout<<"qulified for baoyan" <<endl; } void PrintInfo () CStudent::PrintInfo (); cout<<"Department:" <<department<<endl; } void SetInfo (const string& name_,const string& id_,int age_,char gender_,const string& department_) CStudent::SetInfo (name_,id_,age_,gender_); department=department_; } }; void CStudent::PrintInfo () cout<<"Name:" <<name<<endl; cout<<"ID:" <<id<<endl; cout<<"Age:" <<age<<endl; cout<<"Gender:" <<gender<<endl; } void CStudent::SetInfo (const string& name_,const string& id_,int age_,char gender_) name=name_; id=id_; age=age_; gender=gender_; } int main () CStudent s1; CUndergraduateStudent s2; s2. SetInfo ("Harry Potter" ,"118829212" ,19 ,'M' ,"Computer Science" ); cout<<s2. GetName ()<<" " ; s2. QulifiedBaoYan (); s2. PrintInfo (); cout<<"sizeof(string)=" <<sizeof (string)<<endl; cout<<"sizeof(CStudent)=" <<sizeof (CStudent)<<endl; cout<<"sizeof(CUndergraduateStudent)=" <<sizeof (CUndergraduateStudent)<<endl; return 0 ; }
程序输出为:
1 2 3 4 5 6 7 8 9 Harry Potter qulified for baoyan Name:Harry Potter ID:118829212 Age:19 Gender:M Department:Computer Science sizeof(string)=32 sizeof(CStudent)=72 sizeof(CUndergraduateStudent)=104
从上面的程序中,我们可以获得一些使用派生时的技巧:同名函数的覆写和派生类调用基类同名成员函数 。首先,重写覆盖函数的的方法,在java中我们称为@override,例如上面的程序中CStudent类中的PrintInfo函数,在派生类CUndergraduateStudent中也有这个函数,并且两个并不相同,这时在编译时对于CUndergraduateStudent类的对象将会直接执行后面的函数,就像是派生类中的同名函数覆盖了基类的函数一样。当然类似于java,我们同样仍然可以使用基类被覆盖的函数,在C++中可以使用
1 2 s2.CStudent::PrintInfo(); p->CStudent::PrintInfo();
这样就可以调用基类的同名成员函数了。其次,在派生类的成员函数定义中,如果我们希望使用基类的成员函数,尤其是使用同名成员函数时,可以使用CBase::function进行调用 ,注意如果是同名函数,不在前面声明基类,通常编译器会认为循环定义而报错。
派生类和基类有同名成员函数很常见,但一般不会在派生类中定义和基类同名的成员变量,因为这样会让人困惑,浪费一点点空间让你的代码更有条理也是必要的。
7-9行输出,在不同编译器中的结果是不一样的,我的是在vscode上编译的,如果你再devcpp中运行,结果会不同,不同编译器对于string类的处理是不同的。
复合关系和继承关系的区别 这里 来查看。符合关系也称为“有”的关系(“has a”),例如,一个CStudent类有一个String类的name;而继承关系则是“是”的关系(“is a”),即派生类对象也是一个基类对象,就像前面例子中每一个CUndergraduateStudent对象也是一个CStudent对象。在设计两个有关系的类时要注意,并非两个类有共同点,就可以让它们成为继承关系。让类B继承类A,应该满足“”类B所代表的事物也是类A所代表的事物“。例如下面平面上点的类CPoint:
1 2 3 class CPoint { double x,y; };
我们要继续协议俄国圆形类CCircle。如果我们让这个类从CPoint中派生而来,即写成如下形式:
1 2 3 class CCircle :public CPoint{ double r; };
这是不正确的,因为在逻辑上,这个代码的含义是”圆也是点“,正确的逻辑应该是”圆有一个点“,这个点是圆心。正确的写法如下:
1 2 3 4 class CCircle { double r; CPoint center; };
这是一个逻辑问题,会让你得代码看起来更加可读,虽然在现在这个简单的代码看来,两种定义没有区别,但如果后面引入更多方法后,可能会出现一些逻辑问题。
1 2 3 4 5 6 7 8 class CDog ;class CMaster { CDog* dogs[10 ]; int dogNum; }; class CDog { CMaster m; };
注意,在定义CMaster时,如果使用CDog dog[10],即不使用指针形式,代码是无法编译的,因为出现了循环定义。为了避免循环定义,我们在使用另一个类时,使用另一个类的指针而不是对象。当我们使用指针作为成员变量时,它的地址大小为4个字节,所以编译器不必知道CDog类是什么样子的,而当CMaster对象养了一条狗后,我们可以使用new运算符动态分配一个CDog对象,然后在dogs数组中找到一个元素,让它指向动态分配的CDog对象。
当然这种写法还是不够好,因为当有很多狗共同属于一个主人时,在生成CDog对象时会出现很多完全相同但占用不同存储空间的CMaster对象,这样并不完美,所以我们可以写成如下的形式:
1 2 3 4 5 6 7 8 class CMaster ;class CDog { CMaster* pm; }; class CMaster { CDog dogs[10 ]; int dogNum; };
这样,主人相同的多个CDog对象,其pm指着都是指向同一个CMaster对象的。当然不一定所有主人都养满10条狗,所以CDog dogs[10]可以修改成CDog* dogs[10]这种动态分配空间的形式,所以在这种相互引用的问题中,最好的写法就是通过指针相互指向。
protected访问范围说明符 public、private、protected。public就是在类内外都可以进行访问的成员,private是只有在类内进行访问的成员,我们今天会增加一种在继承关系中承担作用的访问范围说明符protected,事实上,它的访问范围介于public和private之间,在任何私有成员可以进行访问的地方都可以访问保护成员,但是基类的保护成员可以在派生类的成员函数中访问。这就为那些不宜设为公有(防止接口数据被访问),但有需要被其他类继承的成员提供了可行的方案。在基类中,一般都将需要隐藏的成员说明为保护成员而非私有成员。
派生类的构造函数和析构函数 再执行一个派生类对象的构造函数之前,总是先执行基类的构造函数。 这与封闭类的构造函数执行顺序相似(封闭类首先初始化成员对象,然后再执行封闭类的构造函数),其构造函数的初始化列表也与封闭类是相似的,要在列表中指明调用的基类构造函数。当一个派生类由复制构造函数初始化,则基类也是默认使用复制构造函数的。当派生类对象消亡时,先执行派生类的析构函数,再执行基类的析构函数。 例如以下的程序:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 #include <iostream> #include <string> using namespace std;class CBug { int legNum,color; public : CBug (int ln,int cl):legNum (ln),color (cl){ cout<<"CBug constructor" <<endl; } ~CBug (){ cout<<"CBug Destructor" <<endl; } void PrintInfo () cout<<legNum<<"," <<color<<endl; } }; class CFlyingBug :public CBug{ int wingNum; public : CFlyingBug (int ln,int cl,int wn):CBug (ln,cl),wingNum (wn){ cout<<"CFlyingBug constructor" <<endl; } ~CFlyingBug (){ cout<<"CFlyingBug destructor" <<endl; } }; int main () CFlyingBug fb (2 ,3 ,4 ) ; fb.PrintInfo (); return 0 ; }
输出结果为:
1 2 3 4 5 CBug constructor CFlyingBug constructor 2,3 CFlyingBug destructor CBug Destructor
这与我们前面说的一致,当然,如果你尝试给CFlyingBug内加入无参构造函数,编译器就会报错,因为基类没有无参构造函数。
当一个派生类中存在成员对象时,初始化又是如何进行的呢?按照编译器,一般的执行顺序是:先从上到下执行所有基类的构造函数,再按照成员对象的定义顺序执行各个成员对象的构造函数(注意与参数表顺序无关),最后执行自身的构造函数。 而对象消亡时,就会完全反方向执行析构函数,即先执行派生类的析构函数,再按成员对象定义的倒序执行成员对象的析构函数,最后自底向上的执行所有基类的析构函数。
多层次派生 派生类的成员包括派生类自己定义的成员、直接基类中定义的成员,以及所有间接基类的成员。 构造函数和析构函数的执行顺序可以参考上面刚刚提到的派生类同时为封闭类的执行顺序。
公有派生的复制兼容规则以及基类和派生类指针的相互转换 public进行继承时,有以下三条赋值兼容规则:
派生类对象可以赋值给基类对象(保证信息完整的赋值,反过来就不完整,所以反过来就不正确)
派生类对象可以用来初始化基类引用
派生类对象的地址可以赋值给基类指针,派生类对象指针可以赋值给基类指针(即基类指针可以指向的对象更多,包括自己和自己的所有子类)
上面的三条反过来都是不正确的,会出现信息的不完备,或者指针范围的越界。当然后面我们会提到,基类指针强制转化为派生类指针,但我们始终需要注意,这种情况会造成内存的不安全(可以参考图1思考一下安全性问题)。我们不妨来看一个例子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 #include <iostream> #include <string> using namespace std;class A {};class B :public A{};int main () A a; B b; a=b; A& r=b; A *pa=&b; B *pb=&b; pa=pb; return 0 ; }
这个程序没有输出,可以正常运行和编译。第9行我们将派生类的值赋给了基类,第10行,我们将基类引用指向了派生类对象,第11行,我们使用基类指针指向了派生类对象,第13行,我们将派生类指针赋值给了一个基类指针。如果我们没有重载=算符,则上面的第9行表示的就是将b中基类的信息逐个字节的复制到a中。所以,在公有继承的前提下,可以说派生类也是基类,在任何本该出现基类对象的地方,如果出现的是派生类对象也是没有问题的。 但是注意,一定要检查范围是否正确,一定是信息量大的想信息量小的位置赋值或传递信息。
即便一个基类指针指向的是派生类对象,也不能通过基类指针访问基类没有而派生类有的成员 ,因为这会造成编译器的混淆。
基类指针正常情况下不能赋值给派生类指针,但是我们可以通过强制转换指针类型,将一个本来是基类的指针变成一个派生类指针,但是老生常谈的是,这样的转换完全不安全,如果你指向的内容是一个派生类对象还好,如果仅仅是一个基类对象,那么该指针中所有涉及派生类拓展的成员的操作都会出现神奇的错误。我们来看一个小例子来晚上对上面一大坨描述的认识:
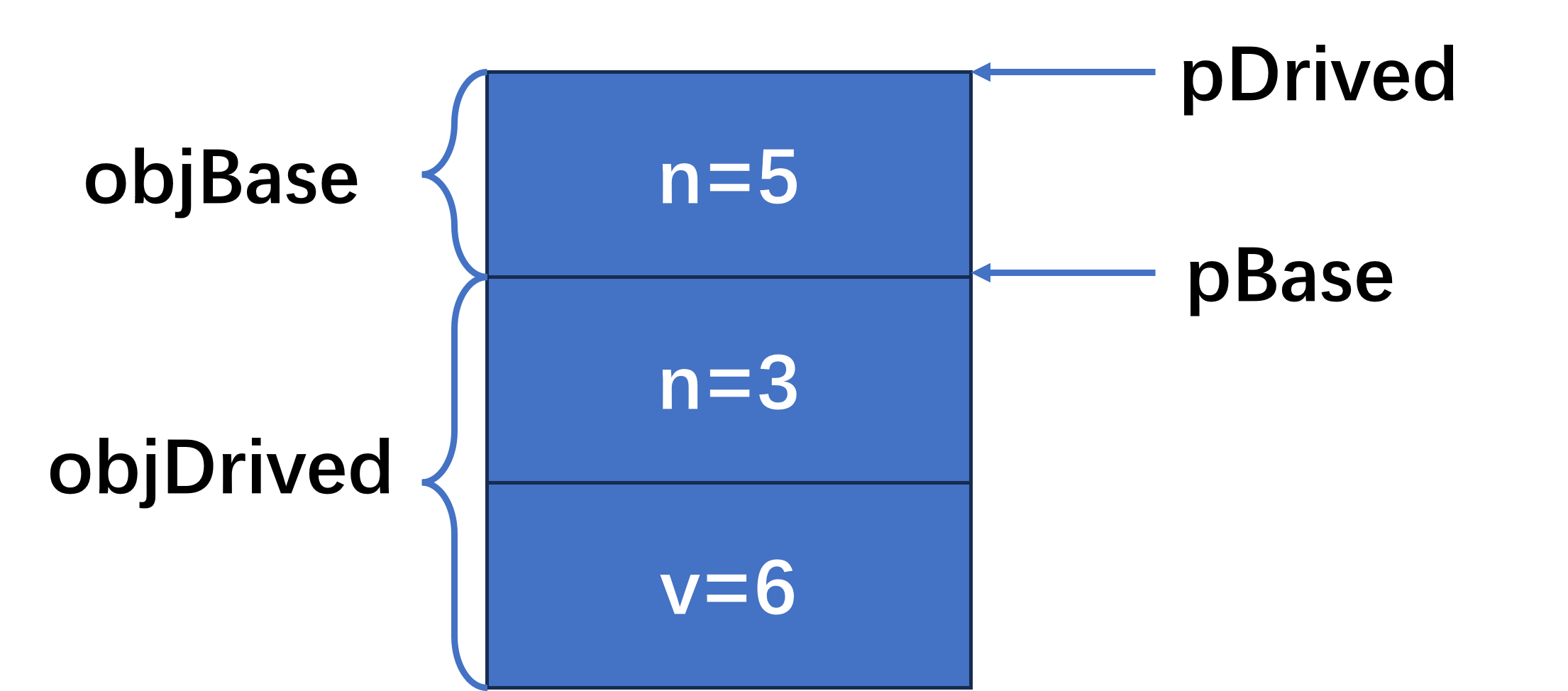
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 #include <iostream> #include <string> using namespace std;class CBase {protected : int n; public : CBase (int n_):n (n_){} void Print () cout<<"CBase:n=" <<n<<endl; } }; class CDrived :public CBase{public : int v; CDrived (int n_):CBase (n_),v (2 *n_){} void Func () void Print () cout<<"CDrived:n=" <<n<<endl; cout<<"CDrived:v=" <<v<<endl; } }; int main () CDrived objDrived (3 ) ; CBase objBase (5 ) ; CBase* pBase=&objDrived; pBase->Print (); cout<<"(1)---------------" <<endl; CDrived* pDrived=(CDrived*)&objBase; pDrived->Print (); cout<<"(2)---------------" <<endl; objDrived.Print (); cout<<"(3)---------------" <<endl; pDrived->v=128 ; objDrived.Print (); return 0 ; }
输出的结果为:
1 2 3 4 5 6 7 8 9 10 CBase:n=3 (1)--------------- CDrived:n=5 CDrived:v=3 (2)--------------- CDrived:n=3 CDrived:v=6 (3)--------------- CDrived:n=128 CDrived:v=6
如果你没有搞清楚程序中的指向问题,不妨画出内存图来分析一下,这样将会更加了解我前面始终强调的安全性问题,可以看到对于pDriver指向内容的修改直接影响到了其他变量的值,这绝对不是我们希望看到的。如果你实在没有搞明白问题,也可以参考图2。
图2:示例代码中存储空间和指针位置的图案描述
当然,基类的引用也可以强制转换称派生类的引用,但是这种有信息量少的量向信息量大的量转换时,始终存在安全性问题,使用时一定要注意。C++中提供了dynamic_cast来判断你的强制转换是否安全,可以结合进行使用。
派生类对象的赋值运算符 =运算符而派生类没有,那么在派生类对象之间进行赋值时,或者派生类对象对基类赋值时,其中基类部分的赋值都是通过调用基类中重载的=运算符进行的。例如:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 #include <iostream> using namespace std;class CBase {public : CBase (){} CBase (CBase& c){cout<<"CBase::copy constructor called" <<endl;} CBase& operator =(const CBase& b){ cout<<"CBase::operator = called" <<endl; return *this ; } }; class CDrived :public CBase{};int main () CDrived d1,d2; CDrived d3 (d1) ; d2=d1; return 0 ; }
输出结果为:
1 2 CBase::copy constructor called CBase::operator = called
在14行调用了赋值构造函数,在15行使用了基类重载的=运算符。